
26.3. Hierarchical Clustering#
Hierarchical clustering is another common approach to unsupervised learning. There are two main types of hierarchical clustering: agglomerative and divisive. Agglomerative clustering is a bottom-up approach, meaning that it starts from individual data points and groups points together. Divisive clustering is the opposite of agglomerative clustering, a top-down approach. Divisive clustering starts with all data points as one large group and then splits them apart into smaller groups. In this section we will focus on the more common of the two techniques: agglomerative hierarchical clustering.
As we mentioned at the end of the previous section, hierarchical clustering does not require us to decide on the number of clusters we want before clustering the data. In addition, it provides the user with a tree-based representation of the relationships between observations called a dendrogram. This is especially useful for data with a hierarchical or nested structure (eg cities within states/provinces within countries or players within teams within leagues).
What are Dendrograms?#
A dendrogram is a tree-diagram representing similarity between datapoints. It is called a tree-diagram because it looks similar to an upside-down tree with the trunk at the top and branches leading to leaves at the bottom. An example of a dendrogram produced by hierarchical clustering is depicted below.
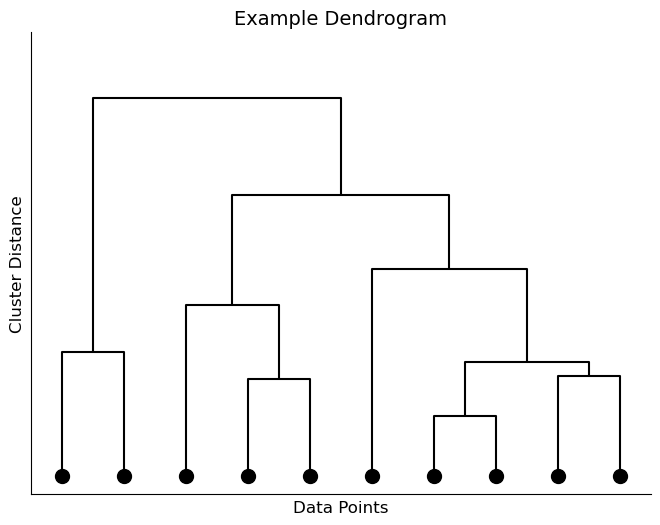
At the bottom of the image are the individual observations in the dataset. These points are gradually linked by branches as we move up the tree until all points are connected at the top. The lower in the tree points are connected, the more similar those points are to each other as deemed by the algorithm. Points that are fused together higher in the dendrogram are less similar to each other. That is, the height on the vertical axis at which points become connected indicates how similar/different the two observations are from each other.
Note
We can only draw conclusions about the similarity between points based on their proximity on the vertical axis not the horizontal axis. Two points being next to each other along the horizontal axis means nothing about their similarity/dissimilarity.
To decide how many clusters we split the data into, we choose a height at which to ‘cut’ the dendrogram. This height is essentially a threshold at which we decide points are far enough away from each other that they shouldn’t belong in the same cluster. Imagine you are cutting through the dendrogram at a certain height; each piece of the tree that falls is a separate cluster. Let’s show an example. Below, I have the same dendrogram as above but I have drawn a line across it at some height t.
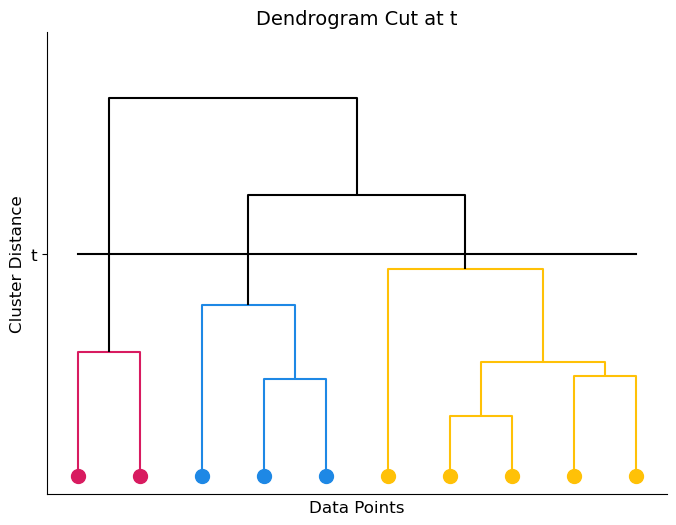
This cut splits the dendrogram (and thus the dataset) into 3 clusters, shown in the image as orange, green, and red. Notice that, depending on where we draw our line, we could cut the dendrogram into any number of clusters. The image below shows a different cut at height t’ which results in only 2 clusters.
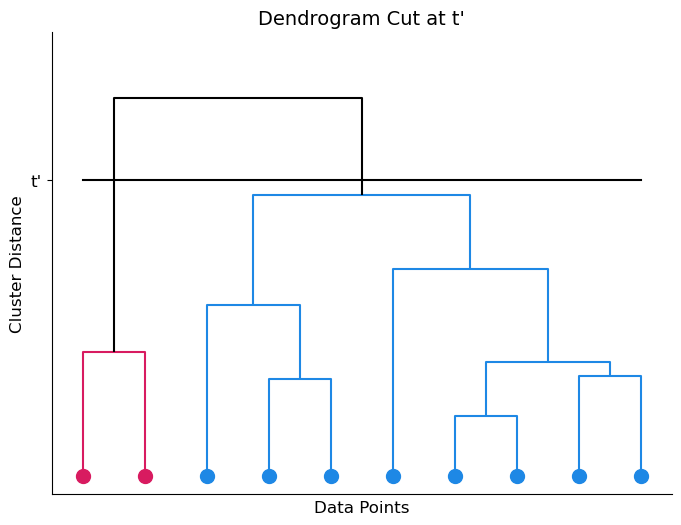
In practice, users often look at the dendrogram and select the number of clusters by eye, based on the fusion heights and domain knowledge.
The Algorithm#
Now that we understand the output of a hierarchical clustering, let’s walk through the algorithm depicted in Algorithm 26.2.
Algorithm 26.2 (Hierarchical Clustering)
Inputs Given a dissimilarity metric and linkage.
Output A dendrogram that can be used to decide on a clustering of \(n\) datapoints.
Begin by treating each of the \(n\) points as its own cluster.
While there exists more than one cluster:
Fuse the two clusters that are closest given the choice of dissimilarity metric and linkage.
We start by treating every observation in our dataset as if it is its own, tiny cluster. Then, we measure the distance between each pair of ‘clusters’ and fuse the two closest clusters together into one larger cluster. Now, we have moved from having \(n\) distinct clusters to having \(n-1\) clusters. One of these clusters contains 2 points, the rest contain only 1. Next, we calculate the distance between each pair of these \(n-1\) clusters and, again, fuse the two closest together. We continue this way until all points belong to one large cluster.
If you look back to our example dendrograms, you can imagine how this algorithm draws the dendrogram from the bottom up, fusing points together until all points have been connected.
Dissimilarity vs Linkage#
You may have noticed we glossed over two important, and commonly confused, terms in Algorithm 26.2: dissimilarity and linkage.
Dissimilarity is another term for distance metric. We’ve talked about distance metrics in the previous section and in more detail in Chapter 23. There are many different ways to measure distance between points and, like in previous chapters, we can use cross-validation to choose a distance metric for our application. Imagine you are trying to calculate Euclidean distance, for example, between two points. As Euclidean distance is the shortest path from one point to the other, it is akin to drawing a straight line between points and measuring that line. We have a formula that we can use to calculate this distance. However, in Algorithm 26.2, we are not always calculating distances between pairs of points. Sometimes, we need to calculate distances between a point and a group of points or between two groups of points. How would we draw a line between two clusters of points? Should we connect the points in each cluster that are closest to each other? Connect the centroids of the two groups? This choice of how to determine distance between clusters is known as linkage.
Some choices for linkage include:
Complete Linkage - calculate distance between the furthest pair of points (shown below left)
Average Linkage - calculate the distance between all pairs of points and take the average (not pictured as it is an average of all pairwise distances)
Centroid Linkage - calculate the distance between the two centroids (shown below center)
Single Linkage - calculate distance between the closest pair of points (shown below right)
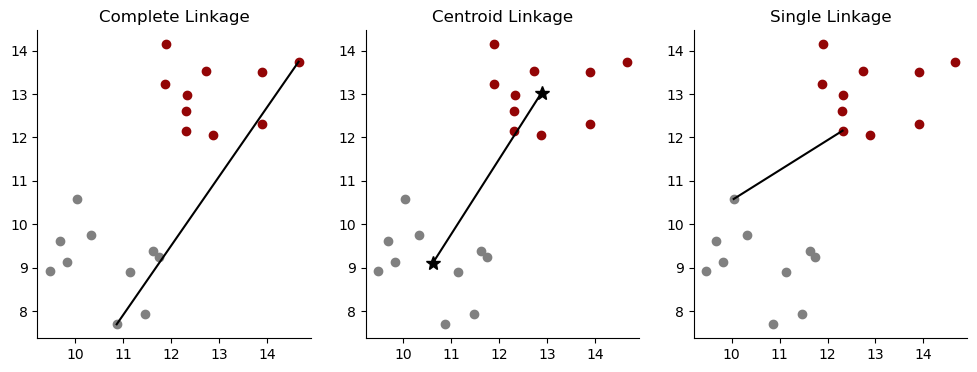
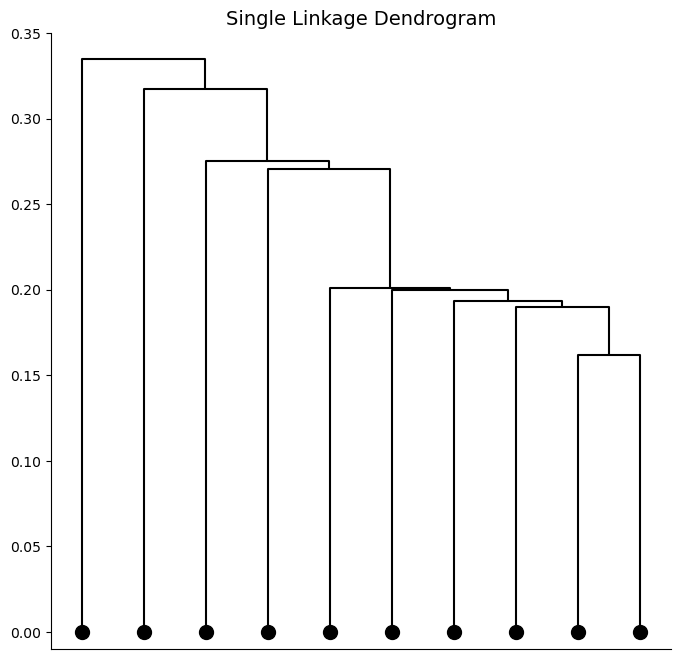
Complete and average linkage are commonly used because they lead to balanced dendrograms (ie no majority clusters). The example dendrogram from earlier would be considered a balanced dendrogram. Single linkage can result in “trailing clusters” where observations tend to be fused one-at-a-time. An example of a dendrogram with trailing clusters is shown below.
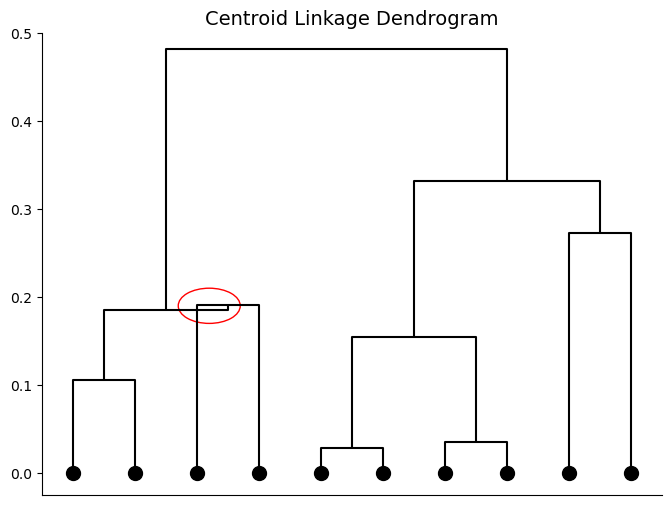
Centroid linkage can result in a dendrogram where clusters are fused at heights below either of the individual cluster heights. This is called inversion and can be hard to visualize or interpret. An example of a dendrogram with an inversion is shown below with the inverted portion circled in red.
Note, the dendrogram with trailing clusters was created using the same data as the example dendrogram from earlier. The only change to the clustering algorithm was the choice of linkage. The linkage chosen in hierarchical clustering, like the choice of distance metric, can have very large effects on our final dendrogram. These choices are often based on the application and are made using a combination of and domain knowledge and trial-and-error. We will investigate this further in the next section with a few examples.